Resolución de sudokus (16)
Interfaz gráfica, refactorización y más corrección de bugs
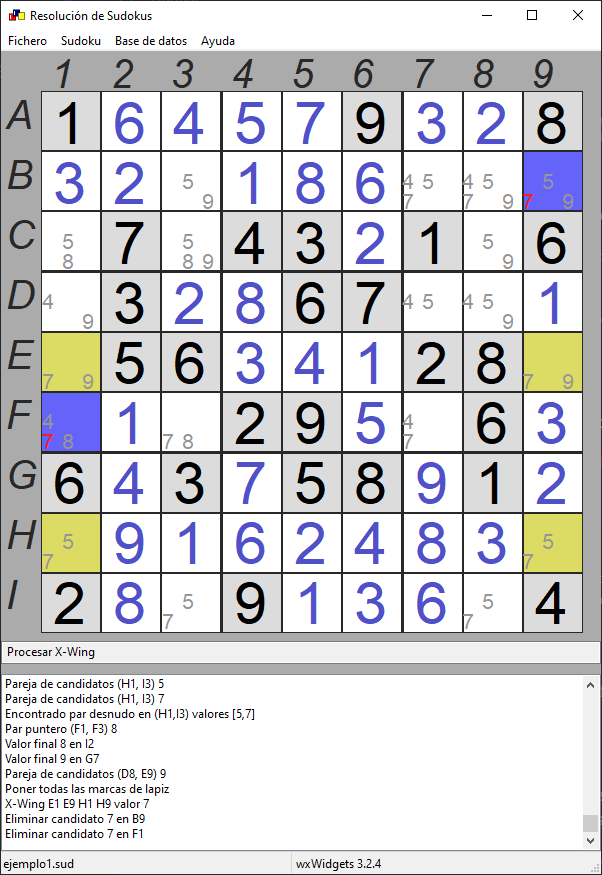
El objetivo de esta entrada es abandonar la aplicación de consola y convertirla a una aplicación GUI, usando wxWidgets.
En el proceso modificaremos varias clases y funciones ya escritas, aunque conservaremos gran parte del código, que es independiente del modo en que se visualizan los procesos.
La idea es que el programa nos enseñe a resolver sudokus utilizando las técnicas que hemos documentado, pero explicando los procesos paso a paso de la forma más detallada y clara que podamos diseñar.
Mostrar el tablero
Para mostrar el tablero en la ventana de la aplicación deberemos procesar el evento EVT_PAINT.
Empezaremos diseñando algunas funciones que eventualmente nos permitan escalar el tablero para adaptarlo a diferentes tamaños de ventana, por si fuese necesario.
Para ello crearemos algunos métodos para mostrar casillas, valores finales y marcas de lápiz:
void OnPaint(wxPaintEvent& event);
void MuestraValor(wxPaintDC& dc, int lado, Casilla& cas);
void MuestraMarcasDeLapiz(wxPaintDC& dc, int lado, Casilla& cas);
Clase MarcasLapiz
Esta es una de las clases que vamos a rescribir. En lugar de usar bits, usaremos un array de valores bool, que aunque cambiará algo el código, probablemente redunde en claridad.
Además corregiremos un error de su operador de resta.
Veamos el error con un ejemplo: si a las marcas correspondientes a 2, 3 y 4, le restamos las correspondientes a las marcas 1 y 2, según el procedimiento original obtendremos las marcas 1, 3 y 4, cuando sólo deberíamos haber obtenido las marcas 3 y 4.
En la práctica este error no influía en la resolución de los sudokus, ya que el operador resta sólo se aplicaba en esta operación, al buscar patrones XY-Wing:
MarcasLapiz nocomunes =
(pivote->Lapiz() | ala1->Lapiz()) - (pivote->Lapiz() & ala1->Lapiz());
El método Quitar hace lo mismo que el operador resta, con la diferencia de que devuelve false si no se elimina ninguna marca de lápiz. Sin embargo, nunca se usa en el código, de modo que podríamos eliminarlo, aunque lo dejaremos, sólo por si acaso.
También cambiaremos los operadores OR y AND, que usaban los símbolos + y ^, para usar | y & que resultan más intuitivos.
Añadiremos un nuevo array de valores bool para almacenar las marcas de lápiz que se han eliminado en el último método aplicado, con el fin de resaltar esos valores en pantalla.
Clase MarcasCasillas
Esta clase funciona de forma parecida a la anterior, aunque a la inversa: en lugar de almacenar los valores de los candidatos para una casilla, almacena los índices de las casillas que contienen un candidato determinado.
También almacena la información en bits, y de nuevo la rescribiremos para usar un array de bools.
Clase Unico
Inicialmente, esta clase sólo contenía los valores del índice y valor de la casilla de un grupo: fila, columna o caja, en la que todas las casillas menos una tenían un valor asignado.
Esto hacía necesario que para cada una de las clases que manejaban de esos grupos hubiese que escribir una función con el mismo código exacto.
Unico Columna::CandidatoUnico() {
bool valor[9] = {false, false, false, false, false, false, false, false, false};
int cuenta = 0;
int i, c;
// Contar valores, si son 8 devolver valor que falta:
for(i=0; i<9; i++) {
if(cas[i]->Valor()) {
cuenta++;
valor[cas[i]->Valor()-1] = true;
} else
c=i;
}
if(cuenta == 8) {
i=0;
while(valor[i++]);
return Unico(c, i);
}
return Unico(-1,0);
}
Esto es redundante, poco eficiente y una posible causa de errores. Sería mucho más lógico que las clases Fila, Columna y Caja derivasen de una clase base común, de modo que pudiéramos usar herencia, ya que hay otros casos similares, y varios métodos de esas tres clases tienen el mismo código. Para ello se ha creado una nueva clase abstracta Grupo de la que se derivan Fila, Columna y Caja.
Pero como previamente ya teníamos una clase llamada Grupo, que se usaba para buscar grupos ocultos, renombraremos esa clase como Oculto.
Clase Tablero
Esta clase es la que más modificaciones precisa.
Ahora queremos que nuestra aplicación muestre los pasos de resolución detalladamente, y debido a que el proceso que visualiza el tablero es parte de una clase derivada de wxFrame, no podemos actualizar esa visualización desde métodos de la clase Tablero.
En lugar de actualizar la pantalla desde la clase tablero como hacíamos hasta ahora, almacenaremos los cambios de aplicar cada método en los objetos Casilla y en otras estructuras.
El bucle de resolución no será ahora un simple bucle, tendremos un método que ejecutará secuencialmente cada método de resolución disponible hasta que uno de ellos aporte información nueva, ignorando aquellos que no la aporten, y sólo entonces actualizaremos la pantalla.
Por ejemplo:
switch(T.Estado()) {
...
case solitarios:
if(T.ProcesarCribaSolitarios()) {
cad = wxString::Format(_T("Procesar criba de candidatos solitarios"));
tecnica->ChangeValue(cad);
T.SetNuevaInfo();
Log();
Refresh(true);
break;
}
case paresdesnudos:
T.BuscaParesDesnudos(); // Actualiza la lista de pares desnudos
if(T.ProcesarParesDesnudos()) {
cad = wxString::Format(_T("Buscar y procesar pares desnudos"));
tecnica->ChangeValue(cad);
Log();
Refresh(true);
break;
}
...
Colocaremos todos los métodos en una sentencia switch, de modo que si uno de ellos aporta información, se actualiza la pantalla y se abandona el switch. Si el método no aporta nueva información, se ejecuta el siguiente método.
Si todos fallan, el último método establece el estado "nosolucionable", o si el sudoku ha quedado resuelto, se establece el estado "resuelto".
Este es el enfoque adecuado al usar aplicaciones orientadas a eventos. Esto hace que muchos de los procedimientos para encontrar patrones y aplicar reglas deban ser reescritos o modificados.
Por ejemplo, en la versión de consola los mensajes de eliminación de candidatos o la detección de patrones se enviaban directamente a la pantalla. En la aplicación GUI esos textos se añaden a un control de lista, pero como queremos mantener el código de resolución (lo que ahora se denomina back-end) separado del código de visualización (front-end), esto ya no es posible. Además, dependiendo del procedimiento, se puede añadir una o varias cadenas a esa lista, de modo que no basta con almacenar una cadena.
Para resolver esto se ha implementado una estructura de cola (queue) en la que se van añadiendo las cadenas que posteriormente se retiran de la cola para añadirlas al control lista.
#include <queue>
...
class Tablero {
private:
std::queue<std::string> msgs;
...
bool Mensaje(std::string& cad) {
if(msgs.empty()) return false;
cad = msgs.front();
msgs.pop();
return true;
}
...
Nuevas opciones
Añadiremos una opción para cargar tableros desde ficheros en disco. Los ficheros tendrán como extensión del nombre la cadena ".sud", estarán en formato de texto, del que los primeros 81 caracteres contendrán los valores iniciales de las casillas, y '0' para las casillas vacías. Cualquier texto después de esos primeros 81 caracteres será ignorado por la aplicación, pero podemos usarlo para añadir comentarios a nuestro gusto.
De momento no se hacen verificaciones de contenido de estos ficheros, de modo que los contenidos inválidos tendrán consecuencias imprevisibles.
Una segunda opción permite importar un sudoku mediante una cadena de texto con el mismo formato que el fichero.
También se han añadido opciones para resolver el sudoku paso a paso, resolverlo por completo o para reiniciar el tablero.
Cada vez que se ejecuta un paso, en la parte inferior se muestra el método aplicado, y en la lista el patrón detectado y las casillas afectadas, ya sea porque se eliminen candidatos, porque se detecten pares o tríos punteros, pares desnudos, etc. o porque se establezca el valor final de una casilla. En la parte del tablero se marcan en color verde las cribas de candidatos, en amarillo y naranja patrones detectados y en azul casillas afectadas. Los candidatos eliminados se muestran en color rojo.
La idea es mostrar al usuario cómo resolver un sudoku usando métodos de resolución que apliquen la lógica.
El propósito de esta serie de artículos es ilustrar el diseño de algoritmos para la detección y procesado de patrones.
Sudoku válido
Nuestro programa, antes de intentar resolver un sudoku, verifica que tiene solución y que esa solución es única. Sin embargo, esta verificación, tal como la hemos implementado hasta ahora, presenta dos problemas:
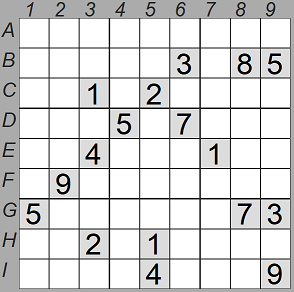
- Si el sudoku tiene muchas soluciones, ya sea porque sea inválido o porque falten pistas, el procedimiento para verificarlo puede requerir mucho tiempo.
- Existen sudokus, por ejemplo el de la imagen de la derecha, que, aún siendo válidos, requieren mucho tiempo para verificarlo usando sólo un método de resolución que use exclusivamente la fuerza bruta.
En el primer caso podemos modificar el procedimiento para que no cuente todas las posibles soluciones, sino que se detenga una vez que se detecte que hay más de una solución:
bool Tablero::FuerzaBruta() {
int f, c, n;
for(f=0; f<9; f++) {
for(c=0; c<9; c++) {
if(casilla[f][c].Valor() == 0) {
for(n=1; n<=9; n++) {
if(Valido(f, c, n)) {
casilla[f][c].Asignar(n);
if(cuenta < 2) // Si hay más de una solución dejar de buscar
if(FuerzaBruta()) return true;
else casilla[f][c].Asignar(0);
}
}
return false;
}
}
}
cuenta++;
return false;
}
En el segundo caso es posible mejorar el método que hemos usado hasta ahora para verificar si sólo hay una solución mediante la "fuerza bruta". Podemos aplicar los métodos de resolución de la fase 1, todos aquellos que se aplican antes de añadir todos los candidatos, para determinar más valores finales de casillas y limitar el número de candidatos en las restantes, de modo que no haya que verificar todos los valores para todas las casillas vacías.
De hecho, en muchos casos, aplicar los métodos de resolución que hemos implementado obtiene el valor de las casillas mucho más rápido que usar la fuerza bruta.
El sudoku del ejemplo es costoso de verificar porque las primeras 14 casillas están vacías, y lo cierto es que ese sudoku está diseñado a propósito para que sea costoso de resolver por fuerza bruta. Una propiedad de los sudokus que también podríamos aprovechar es que se pueden intercambiar dos filas o columnas de la misma fila o columna de cajas, y sigue siendo válido. También podemos intercambiar posiciones de filas y columnas de cajas. En este caso podíamos intentar intercambiar filas o columnas para que en las primeras filas no hubiese tantas casillas vacías.
También podríamos intentar implementar algoritmos como ramificación y poda.
Depuración de código
La implementación de los algoritmos para buscar y procesar patrones es, en muchos casos, complicada, y es fácil cometer errores.
Debido a que esos algoritmos los hemos estado probando con ejemplos concretos, y que no es fácil encontrar sudokus de ejemplo para probar todas las posibles variaciones de un método concreto, algunos de esos errores persisten desde hace tiempo sin que los hayamos detectado.
Por ese motivo es recomendable someter al programa a varias baterías de pruebas que nos ayuden a detectar esos errores.
Yo he detectado cuatro posibles tipos de errores:
- Como nuestro programa aún no es capaz de resolver todos los sudokus, puede suceder que no encuentre una solución por un error en la implementación de algún método, en lugar de por la falta de un procedimiento adecuado. Si el error hace que se eliminen candidatos que no deberían haber sido eliminados, el tablero puede terminar con casillas para las que no queden posibles candidatos.
- Por otra parte, puede suceder lo contrario, que algún procedimiento no elimine candidatos que debería haber eliminado. Ese caso es menos deseable, ya que no podremos detectar el error fácilmente, puesto que el método que falla sencillamente no hace su trabajo completamente, pero al no eliminar candidatos válidos no provoca que alguna casilla se quede sin candidatos, aunque deja sin eliminar candidatos que podrán haber hecho posible encontrar la solución.
- Un tercer tipo de error puede hacer que el programa complete todo el tablero, pero que lo haga de un modo no permitido. Por ejemplo, colocando el mismo valor varias veces en una fila, columna o caja.
- El cuarto tipo de error es el más catastrófico, y hace que el programa se cierre. Esto ocurre al acceder a punteros nulos o por algún otro error grave.
Para hacer estas pruebas he descargado varios conjuntos de sudokus desde Free Printable Sudoku Puzzles, los he introducido en una base de datos SQLite, y he creado una variante de la aplicación que intenta resolverlos usando los métodos ya implementados en nuestro programa, almacenando en la base de datos si se han podido resolver sin error, o si al fracasar la resolución han quedado casillas sin candidatos.
Los puzzles que dan error se cargan posteriormente por separado, se resuelven paso a paso para detectar el método que falla, y para que se pueda depurar el código.
Esta base de datos también nos permite encontrar sudokus que nos ayuden a ilustrar la detección y procesado de ciertos patrones. Para ello se añaden modificaciones que añadan comentarios a la base de datos cuando se aplica algún método concreto.
Usando éste sistema se han encontrado hasta ahora errores en varios métodos, como el del "Pez espada con alas", en "Sashimi", en "X-Wing con alas", en el procesamiento de pares desnudos y también en el procedimiento para añadir todas las marcas de candidatos.
Por ejemplo, uno de los errores más serios que se ha manifestado afecta al método de "Patrones de solución única B", que ha resultado ser incompleto, y que hay que modificar.
Si repasamos los métodos de patrón de solución única de tipo A, vemos que había una condición que no tuvimos en cuenta en el tipo B: que el par desnudo esté en una caja. Esto elimina como candidatos los dos valores del par desnudo en el resto de la caja, y hace que el método funcione.
Para el tipo B deberemos aplicar la misma condición, que originalmente no aplicábamos:
bool Tablero::SolucionUnicaB() {
int ff, cc;
LimpiaResaltes();
desnudo.Primero();
while(desnudo.Actual() && desnudo.ValorActual().MismaCaja()!=-1) {
ff = desnudo.ValorActual().MismaFila();
cc = desnudo.ValorActual().MismaColumna();
if(-1 != ff && desnudo.ValorActual().Par()) { // El par desnudo está en una fila
// Buscar en filas
if(BuscaFilaTrios(desnudo.ValorActual())) return true;
}
if(-1 != cc && desnudo.ValorActual().Par()) {
if(BuscaColumnaTrios(desnudo.ValorActual())) return true;
}
desnudo.Siguiente();
}
return false;
}
El sudoku que descubrió este fallo fue el que ocupaba la posición 6348 en la base de datos de sudokus con 25 pistas.
Otro problema es encontrar sudokus que nos permitan probar si ciertos procedimientos funcionan. Por ejemplo, para verificar que la detección de patrones de solución única de tipo C (que veremos en el próximo artículo) sólo he encontrado dos sudokus, y los dos son de tipo A.
En el futuro espero poder aplicar pruebas unitarias a algunos de los métodos para verificar si funcionan en cualquier situación posible.
Se han modificado bastantes cosas en el código usado hasta el artículo anterior. En los siguientes usaremos el código actual como base para seguir añadiendo métodos de resolución, y eventualmente corregir posibles errores no detectados hasta ahora.
Se han detectado y corregido muchos otros errores, por ejemplo, al procesar los pares desnudos, ya que se procesaban también aquellos que estaban marcados para borrar. Recordemos que se marcan para borrar los pares desnudos correspondientes a casillas con valores finales. Esto provocaba que se considerasen como candidatos valores que ya estaban asignados a un grupo (fila, columna o caja).
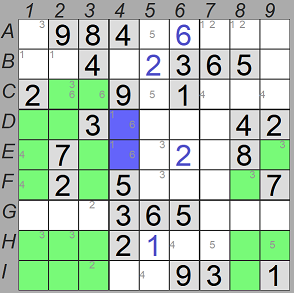
Pares desnudos
Hablando de pares desnudos, resolviendo un sudoku paso a paso me di cuenta de que no estaba detectando a tiempo ciertos pares desnudos. Por ejemplo, en el sudoku de la derecha, en un momento dado en las casillas D4 y E4 se detectan dos pares punteros con valores 1 y 6. Esto es, definitivamente un par desnudo que no se detectaba durante las cribas. Posteriormente se detecta otro par puntero para las casillas D4 y D6 con valor 7, pero no debería ser así, ya que D4 formaba parte de un par desnudo, no debería admitir un tercer candidato, y deberíamos haber asignado el valor 7 directamente a la casilla D6.
La misma situación se repite otras veces en el mismo sudoku, por ejemplo, en las casillas C7 y C9, con los valores 4 y 8, en que posteriormente se asigna el par puntero 7 a las casillas C7 y C8, o las casillas F5 y F6 con los valores 4 y 8, en que se asigna el par puntero 9 a las casillas D5 y F5.
Detectar estas situaciones nos ahorraría muchas iteraciones de criba, y resolvería el sudoku más rápido, y lo que es más importante, de una forma más intuitiva.
Para hacerlo, cada vez que marquemos un par puntero o una pareja de candidatos tendremos que verificar si en las mismas casillas ya se había marcado previamente otro. En ese caso, añadiremos un par desnudo a la lista de pares desnudos.
Por otra parte, los pares desnudos también se pueden eliminar en las cribas para todos los valores menos para los que forman parte del par desnudo. Por ejemplo, si en una fila tenemos el par desnudo A4 y A5 con los valores 1 y 2, podremos marcar como no posibles esas dos casillas para todos los valores menos el 1 y el 2.
De modo que también tendremos que completar el proceso de criba para que tenga en cuenta los pares desnudos, algo que hasta ahora no se hacía.
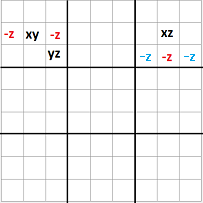
Patrones XY-Wing
Otro ejemplo de método de eliminación de candidatos que no estaba correctamente implementada es el XY-Wing.
En el artículo sudoku 7 detectamos y procesamos patrones XY-WIng, pero el procesado no era correcto porque el algoritmo no estaba completo. Es un caso de error de diseño, el código era correcto, pero partimos de un algoritmo erróneo.
En la imagen de la izquierda podemos ver un patrón XY-Wing en una fila de columnas tal como lo procesábamos en el artículo 7. El patrón es correcto, pero al procesarlo hemos omitido algunas casillas en las que podemos eliminar candidatos.
Repasemos el algoritmo. Para el caso 1, donde el pivote y las alas están en cajas diferentes, sólo se puede eliminar el candidato común en las dos alas en una casilla. Esta parte del algoritmo es correcta.
En el caso 2, tenemos dos posibilidades:
- Que en el pivote tengamos en valor x. Esto implica que el valor z estará en la casilla de la caja de la derecha, eliminando como candidato z del resto de casillas de esa caja. También elimina el candidato z de su fila en la caja de la izquierda.
- Que en el pivote tengamos el valor y. Esto implica que z estará en la casilla de la caja izquierda, eliminando como candidato z del resto de la caja. También elimina el candidato z en esa fila en la caja de la derecha.
Las casillas en las que se puede eliminar z como candidato en ambos casos son las de la fila del ala derecha en la caja de la izquierda y las de la fila del ala izquierda en la caja de la derecha. Es decir, tenemos dos casillas más en las que podríamos eliminar z como candidato, siempre que no contengan un valor final y que tengan z como candidato, las marcadas en azul.
Mejoras en métodos
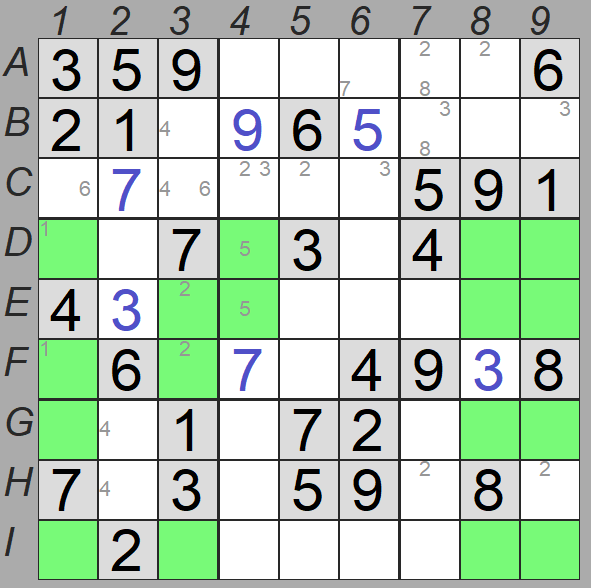
Observando al programa resolver algunos sudokus he detectado que veo que antes de añadir todos los candidatos, algunos patrones al programa le pasan desapercibidos. Por ejemplo, en el sudoku de la derecha, haciendo la criba con el valor 5, a mi me resulta bastante claro que en la caja 4 las casillas F1 y F3 contienen un par puntero con valor 5, ya que no es posible colocar ese valor en la fila F de las cajas 5 y 6.
Puede parecer que ese par puntero no aporta información útil, ya que no elimina candidatos en la fila F, pero sí los elimina en la caja 4, y si posteriormente se asigna un valor a cualquiera de las casillas F1 o F3, podremos colocar el valor 5 en la otra.
Considero que, al menos a la hora de calcular la dificultad de un sudoku, todo lo que pueda hacerse antes de añadir todos los candidatos indicará que el sudoku es más sencillo.
Por lo tanto también se ha modificado el método Criba y de ProcesarCriba para detectar estos patrones y aplicarlos.
El método de procesar la criba se ha reescrito por completo. Ahora se orienta a buscar filas o columnas con una, dos o tres casillas posibles. En caso de encontrar una fila o columna con una única casilla posible, se asigna el valor. En caso de dos o tres casillas posibles, hay que verificar si están en la misma caja, en cuyo caso caso tendremos un par o trio puntero. Posteriormente se buscan cajas con dos casillas posibles en diferentes columnas y filas.
Esto también afecta a cómo se procesan las cribas, ya que ahora tenemos pares y tríos punteros que no se deducen del mismo modo que antes, y que sólo sirven para eliminar candidatos en la caja donde estén. Del mismo modo afecta al método para añadir todas las marcas de lápiz.
Para procesar las cribas lo haremos por filas y columnas.
Para cada fila contamos las casillas en las que es posible el candidato después de aplicar la criba.
- Si sólo hay una casilla posible, asignaremos el valor final.
- Si hay dos casillas, y están en la misma caja, añadiremos el valor como candidato a las casillas, verificaremos si además se trata de un par desnudo y almacenaremos el par puntero.
- Si hay tres casillas, y están en la misma caja, almacenaremos el trio puntero.
// Procesar la criba
for(f=0; f<9; f++) {
// Contar posibles en cada fila
switch(fila[f].CuentaPosibles()) {
case 1: // Valor final
c=fila[f].UnicoPosible();
Asignar(f, c, v);
casilla[f][c].Resaltar();
sprintf(m, "Valor final %d en %s" , v, casilla[f][c].Nombre());
msgs.push(m);
return true;
case 2: // Posible par puntero
c1 = fila[f].PrimeroPosible();
c2 = fila[f].SegundoPosible(c1);
k = casilla[f][c1].Caja();
// Si las dos casillas están en la misma caja y no había sido detectado antes, añadir par puntero
if(k==casilla[f][c2].Caja() && caja[k].AsignaPunteroFila(f%3, v, 2)) {
casilla[f][c1].Lapiz().AsignaMarca(v);
casilla[f][c2].Lapiz().AsignaMarca(v);
casilla[f][c1].Resaltar();
casilla[f][c2].Resaltar();
sprintf(m, "Par puntero (%s, %s) %d", casilla[f][c1].Nombre(), casilla[f][c2].Nombre(), v);
msgs.push(m);
// Verificar además si se trata de un par desnudo:
VerificarParDesnudo(&casilla[f][c1], &casilla[f][c2], v);
return true;
}
break;
case 3: // Posible trio puntero
c1 = fila[f].PrimeroPosible();
c2 = fila[f].SegundoPosible(c1);
c3 = fila[f].TerceroPosible(c2);
k = casilla[f][c1].Caja();
// Si las tres casillas están en la misma caja y no había sido detectado antes, añadir trio puntero
if(k==casilla[f][c2].Caja() && k==casilla[f][c3].Caja() && caja[k].AsignaPunteroFila(f%3, v, 3)) {
casilla[f][c1].Resaltar();
casilla[f][c2].Resaltar();
casilla[f][c3].Resaltar();
sprintf(m, "Trio puntero (%s, %s, %s) %d", casilla[f][c1].Nombre(), casilla[f][c2].Nombre(), casilla[f][c3].Nombre(), v);
msgs.push(m);
return true;
}
break;
}
}
El procedimiento para procesar las columnas es similar.
También tendremos que procesar cada caja para buscar parejas de candidatos que no formen un par puntero:
for(k=0; k<9; k++) {
if(caja[k].CuentaPosibles() == 2) {
p1 = caja[k].PrimeroPosible();
p2 = caja[k].SegundoPosible(p1);
if(!caja[k].Cas(p1)->Lapiz().ContieneMarca(v) || !caja[k].Cas(p2)->Lapiz().ContieneMarca(v)) {
caja[k].Cas(p1)->Lapiz().AsignaMarca(v);
caja[k].Cas(p2)->Lapiz().AsignaMarca(v);
caja[k].Cas(p1)->Resaltar();
caja[k].Cas(p2)->Resaltar();
sprintf(m, "Pareja de candidatos (%s, %s) %d", caja[k].Cas(p1)->Nombre(), caja[k].Cas(p2)->Nombre(), v);
msgs.push(m);
VerificarParDesnudo(caja[k].Cas(p1), caja[k].Cas(p2), v);
return true;
}
}
}
Para aplicar las cribas tendremos que usar los valores finales para eliminar casillas como posibles, en las filas, columnas y cajas en las que estén.
for(int i=0; i<9; i++) {
if(fila[i].Presente(v)) fila[i].Criba();
if(columna[i].Presente(v)) columna[i].Criba();
if(caja[i].Presente(v)) caja[i].Criba();
}
También tendremos que procesar los pares y tríos puntero de una forma análoga.
for(int f=0; f<3; f++) { // Fila de cajas
for(int c=0; c<3; c++) { // Columna de cajas
for(int i=0; i<3; i++) { // Fila de punteros
if(caja[ncaja].PunteroFila(i, v)) {
fila[f*3+i].CribaMenosCaja(c);
for(int p=0; p<9; p++) { // Resto de la caja
if(p/3 != i) caja[ncaja].Cas(p)->MarcaNoPosible();
}
}
}
for(int i=0; i<3; i++) { // Columna de punteros
if(caja[ncaja].PunteroColumna(i, v)) {
columna[c*3+i].CribaMenosCaja(f);
for(int p=0; p<9; p++) { // Resto de la caja
if(p%3 != i) caja[ncaja].Cas(p)->MarcaNoPosible();
}
}
}
ncaja++;
}
}
Por último, procesaremos los pares desnudos para eliminar más casillas como posibles.
Otra modificación necesaria es que cuando se asigne un valor a una casilla que forme parte de un par desnudo, ese par desnudo debe ser destruido.
Más sobre el procesamiento de pares desnudos
El tratamiento de los pares desnudos es diferente en la fase 1, antes de añadir todos los candidatos, que en la fase 2, después de añadirlos.
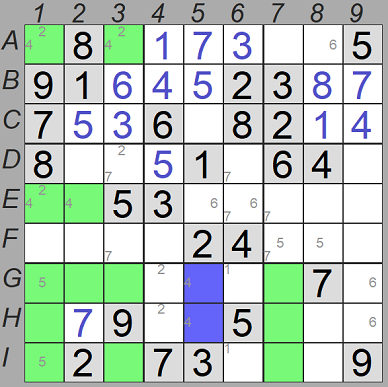
En la fase 1, sólo nos interesa detectar y procesar ciertos pares desnudos, ya que no podemos asegurar que los que podamos detectar en la misma fila o columna, cuando están en distintas cajas, sean realmente pares desnudos. Sólo lo serán si las dos casillas formaban además parte de un par desnudo en sus respectivas cajas. Pero en fase 1 debemos ignorar incluso los pares desnudos en filas o columnas que ocupen cajas diferentes, ya que añadir esos candidatos pueden inducir a error.
Por ejemplo, en el sudoku de la izquierda, podría parecer que las casillas A1 y E1 forman un par desnudo, pero no podemos suponer que en E1 no aparezcan más candidatos además del 2 y el 4. De hecho, cuando la resolución avanza y añadimos todos los candidatos, en E1 también se añade el valor 1, que además será el valor final de esa casilla.
Hasta ahora usábamos dos métodos diferentes para detectar pares desnudos y otros dos para procesarlos, dependiendo de si estábamos en la fase 1 o la 2.
La idea es usar un único método para cada tarea.
En la búsqueda de pares desnudos, durante la fase 1 sólo los buscaremos en cajas. De ese modo evitaremos la detección de falsos pares desnudos. Durante la fase 2 buscaremos también por filas y columnas.
A la hora de procesar los pares desnudos nos limitaremos a buscar casillas con valor final o nuevos pares desnudos ocultos. En cribas posteriores, los nuevos pares desnudos pueden convertirse en valores finales si se puede eliminar alguno de los candidatos en cualquiera de las dos casillas.
Para procesar los pares desnudos usaremos otra técnica:
Considerando únicamente los valores finales y los pares desnudos, contaremos las casillas libres en cada fila, columna y caja. Si únicamente queda una casilla libre en uno de esos grupos, podremos asignarle un valor final. Si quedan dos casillas libres, y en el caso de filas o columnas ambas están en la misma caja, añadiremos el par desnudo correspondiente. Cuando procesemos por cajas, las dos casillas estarán en la misma caja, así que siempre podremos añadir el par desnudo detectado.
En el sudoku del ejemplo, en la fila A sólo quedan dos casillas libres: A7 y A8, y dos candidatos sin usar: 6 y 9, de modo que podemos añadir ese par desnudo. Obviemos en este momento que en A8 hay un 6, ya que sólo estamos considerando valores finales y pares desnudos. Ese 6 se asignará en la siguiente operación de criba.
Del mismo modo, en la fila C sólo queda una casilla libre, C5, y un candidato sin usar, el 9, así que podemos asignarlo.
Esto también hace innecesario el procedimiento de buscar grupos con ocho valores finales, que queda como un caso particular de este método.
En la fase 2, cuando ya se hayan marcado todos los candidatos, también consideraremos pares desnudos los detectados en filas y columnas, aunque no estén en la misma caja.
Pero toda esta tarea será más simple si en lugar de usar una lista enlazada para almacenar pares desnudos usamos la clase Casilla para almacenar la información referente a pares desnudos.
Como curiosidad explicaré cómo ha evolucionado el diseño del programa y las diferentes fases por las que ha pasado la implementación del algoritmo, al menos en el modo en que yo programo.
En una primera aproximación pensé que bastaría con una bandera que indique si la casilla forma parte de un par desnudo, los valores del par serán sus marcas de lápiz. Pero pronto vi que eso no sería suficiente, ya que dificultaba en exceso la detección de la casilla que completa el par desnudo. En su lugar opté por guardar un puntero a la otra casilla que formaba el par desnudo, en ambas casillas.
Bien, esto funcionaba muy bien en fase 1, pero en la fase 2 volvieron a surgir problemas. En fase 1 una casilla sólo puede formar parte de un par desnudo, y un par desnudo siempre está en una caja, aunque además puede estar en una fila, una columna. Sin embargo, en la fase 2, una casilla puede formar parte de dos pares desnudos, y esta solución no funciona.
Es muy frustrante cuando inviertes varias horas en desarrollar, corregir y depurar algunas funciones que al final no funcionan por un error de análisis o diseño.
Pero no quise volver a usar la lista enlazada, de modo que intenté otra solución. En lugar de almacenar un puntero, almacenaremos tres, a fin de cuentas, un par desnudo estará en una fila, una columna o una caja. Incluso en el caso de que forme parte de varios pares desnudos, no existen más de tres posibilidades, cada par estará en una fila, una columna y/o una caja.
Hay que reescribir todos los métodos que trabajan con pares desnudos: criba y su procesado, detección de pares desnudos y su procesado y la adición de todos los candidatos. Además de modificar la clase Casilla.
De este modo podemos usar los mismos métodos para detectar y procesar pares desnudos en fase 1 y fase 2. En próximos artículos veremos que esos pares desnudos son útiles para detectar nuevos patrones.
| Nombre | Fichero | Fecha | Tamaño | Contador | Descarga |
|---|---|---|---|---|---|
| Sudoku 21 | sudoku21.zip | 2025-03-22 | 45328 bytes | 669 |