Compresión RLE

El algoritmo de compresión RLE fue muy utilizado en la época de los procesadores de ocho bits, y aún se usa para la compresión de imágenes en ciertos formatos como BMP, o PCX.
Es un algoritmo de compresión sin pérdida, que consigue resultados aceptables con imágenes con grandes zonas del mismo color, aunque no es muy bueno comprimiendo fotografías.
En su versión más simple los datos se dividen en parejas de valores de tipo byte. El primer valor es un contador y el segundo uno de los datos.
Por ejemplo, si vemos el contenido del fichero de la imagen que ilustra este artículo, suponiendo que no hay compresión ni metadatos, tenemos la siguiente secuencia de bytes:
FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF 8B BE B9 85 AD A9 C4 C4 C4 C4 C4 C4 C4 C4 C4 C4 C4 C4 E9 E9 E9 FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF F1 F1 F1 C4 C4 C4 C4 C4 C4 C4 C4 C4 C4 C4 C4 85 AD A9 68 AA A4 F4 F9 F8 FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF 00 00 FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF A3 CB C7 46 97 8F 9D C1 BD D9 D9 D9 D9 D9 D9 D6 D6 D6 C4 C4 C4 DA DA DA FF FF FF FF FF FF FF FF FF FF FF FF FF FF ...
Podemos crear la siguiente secuencia:
45 FF 01 8B 01 BE 01 B9 01 85 01 AD 01 A9 0C C4 03 E9 72 FF 03 F1 0C C4 01 85 01 AD 01 A9 01 68 01 AA 01 A4 01 F4 01 F9 01 F8 42 FF 02 00 42 FF 01 A3 01 CB 01 C7 01 46 01 97 01 8F 01 9D 01 C1 01 BD 06 D9 03 D6 03 C4 03 DA 0E FF ...
Está bastante claro que si hay muchas repeticiones de valores, el algoritmo consigue buenos ratios de compresión.
Ya que una repetición de cero valores no se va a producir nunca, el valor 0 se puede usar para indicar el valor 256, o, como se hace en la versión oficial del algoritmo, el valor del contador que se almacena es una unidad inferior, de modo que el valor 0 indica una repetición, el 1 dos repeticiones, etc.
Hay que tener en cuenta que la secuencia más larga que se puede almacenar es de 256 datos, por lo tanto, si encontramos una secuencia más larga tendremos que dividirla en subsecuencias de 256 datos y una última con el resto.
Diagrama de flujo
Creo que la mejor manera de visualizar el algoritmo es mediante un diagrama de flujo:
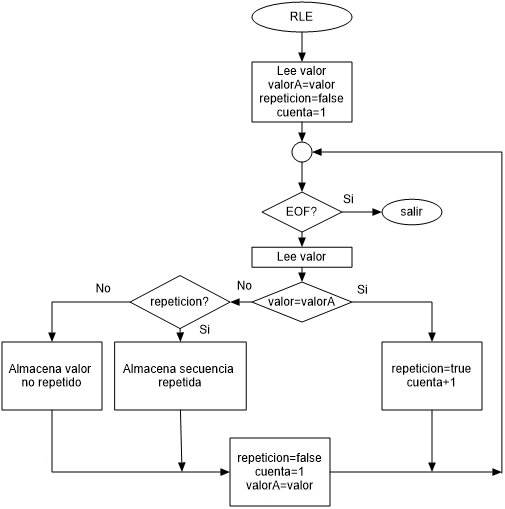
Nuestro programa para comprimir ficheros BMP usando este algoritmo podría quedar así:
#include <iostream>
#include <fstream>
#include <iomanip>
//using namespace std;
/* Cabecera BMP:
00: 42 4D BM -> Firma
02: -- -- -- -- -> Tamaño del archivo
06: -- -- -> Reservado
08: -- -- -> Reservado
0A: -- -- -- -- -> Inicio de datos de imagen
0E: -- -- -- -- -> Tamaño de la cabecera
12: -- -- -- -- -> Anchura en pixels
16: -- -- -- -- -> Altura en pixels
1A: -- -- -> Número de planos de bits
1C: -- -- -> Tamaño del punto
1E: -- -- -- -- -> Compresión (0-> No comprimido)
22: -- -- -- -- -> Tamaño de la imagen
26: -- -- -- -- -> Resolución horizontal
2A: -- -- -- -- -> Resolución vertical
2E: -- -- -- -- -> Tamaño de la paleta
32: -- -- -- -- -> Cuenta de colores importantes
*/
void AlmacenaNoRepetida(std::fstream &fs, unsigned char valor) {
unsigned char cuenta = '\001';
// Guardamos el dato:
fs.write(reinterpret_cast<char*>(&cuenta), 1);
fs.write(reinterpret_cast<char*>(&valor), 1);
}
void AlmacenaRepetida(std::fstream &fs, int cuenta, unsigned char valor) {
unsigned char cuenta256 = '\000';
// Ahora almacenamos los grupos de 256 elementos, si los hay
while(cuenta>256) {
fs.write(reinterpret_cast<char*>(&cuenta256), 1);
fs.write(reinterpret_cast<char*>(&valor), 1);
cuenta -= 256;
}
// Guardamos el resto, si queda:
if(cuenta) {
fs.write(reinterpret_cast<char*>(&cuenta), 1);
fs.write(reinterpret_cast<char*>(&valor), 1);
}
}
int main(int argc, char* argv[])
{
int inicio;
if(argc < 3) {
std::cout << "Usar: RLE <entrada.BMP> <salida.RLE>" << std::endl;
return 0;
}
std::fstream fe(argv[1]);//, std::ios::binary);
if(!fe.is_open()) {
std::cout << "Fichero no encontrado" << std::endl;
return 0;
}
std::fstream fs(argv[2], std::ios::out | std::ios::binary);
// El comienzo de los datos se almacena en la posición 0x0A
fe.seekg(0x0a);
fe.read(reinterpret_cast<char*>(&inicio), 4);
std::cout << "Inicio de datos: " << inicio << std::endl;
// Generar fichero de salida:
fe.seekg(inicio);
unsigned char valor;
unsigned char valorAnt;
int cuenta=1;
bool repetido= false;
fe.read(reinterpret_cast<char*>(&valor), 1);
valorAnt=valor;
while(!fe.eof()) {
fe.read(reinterpret_cast<char*>(&valor), 1);
if(!fe.eof()) {
if(valor==valorAnt) {
repetido = true;
cuenta++;
} else {
if(repetido) {
// Almacena secuencia repetida
AlmacenaRepetida(fs, cuenta, valorAnt);
} else {
// Almacena secuencia no repetida
AlmacenaNoRepetida(fs, valorAnt);
}
repetido=false;
valorAnt=valor;
cuenta=1;
}
} else {
// Ultima secuencia:
if(repetido)
AlmacenaRepetida(fs, cuenta, valorAnt);
else
AlmacenaNoRepetida(fs, valorAnt);
return 0;
}
}
}
El fichero de salida no contiene las cabeceras, solo comprime los datos correspondientes a los pixels, y se incluye solo como un experimento.
Con la imagen del ejemplo este algoritmo no consigue comprimir los datos. El fichero resultante es más grande que el original.
Variantes
Este es el algoritmo oficial de compresión RLE, que a mi entender tiene algunas desventajas que puede hacer que la compresión sea peor, o incluso inexistente para ciertos conjuntos de datos, aunque existan secuencias largas de valores repetidos.
El mayor inconveniente se produce si hay muchas secuencias de valores sin repetición, ya que para cada uno de esos valores se usan dos bytes, y en casos límite la compresión obtenida al empaquetar valores repetidos se pierde con estas secuencias.
Hace muchos años, en los tiempos de los microordenadores de 8 bits, cuando había que almacenar los datos en cintas de cassette, conseguir buenas compresiones de datos redundaba en menor tiempo de carga y guardado de los datos.
Esto era especialmente notable con las imágenes de pantalla. Por ejemplo, en un ZX-Spectrum la pantalla tenía 256x192 pixels, agrupados de ocho en ocho. Los datos de color se almacenaban de forma diferente, y para cada cuadrado de 8x8 pixels se usaba un byte que codificaba los colores de primer y segundo plano, tres bits para cada uno, un bit de parpadeo y otro de brillo.
Es decir 6144 bytes correspondiente a pixels, más 768 para los colores, en total 6912 bytes. Con una velocidad de carga de unos 1.200 baudios, una pantalla requería casi un minuto.
¿Y por qué cuento todo esto? Bueno, uno de mis primeros programas en ensamblador para Z80 fue un compresor de pantallas, cuyo algoritmo sin yo saberlo, se perecía mucho a RLE.
Pero tenía una variante muy interesante. Los valores repetidos se almacenan del mismo modo que en el algoritmo RLE, pero para las secuencias no repetidas se usa un valor especial a modo de marca, un contador con el número de valores de la secuencia sin repeticiones y a continuación la secuencia sin repeticiones completa.
De este modo las secuencias sin repeticiones no duplican el tamaño, y los casos desfavorables se presentan cuando abundan las secuencias no repetidas cortas. Con secuencias de un dato se triplica el espacio requerido, pero aún así se consiguen ratios de compresión mucho mejores que con el algoritmo RLE.
La desventaja es que deberemos leer los datos de las secuencias no repetidas dos veces, o almacenar en memoria esas secuencias.
Para empezar, necesitamos un valor para usar como marca, y el mejor candidato es el 1, ya que nunca vamos a usar ese valor como contador para secuencias repetidas (una secuencia de longitud uno no es una repetición). También podríamos usar el cero, pero reservaremos ese valor para secuencias de 256 datos.
En el caso de que tengamos secuencias de más de 256 datos, las dividiremos en subsecuencias de 256, y una final con el resto.
Esto nos plantea un problema con secuencias de 257 datos repetidos, ya que el resto es 1, y ese es el valor de la marca. Para evitar esto, si el resto del tamaño de la secuencia entre 256 es 1, para el primer grupo usaremos el valor 254, de modo que el último tenga 2 elementos.
El ejemplo anterior, usando un valor de marca 01, quedaría así:
45 FF 01 06 8B BE B9 85 AD A9 0C C4 03 E9 72 FF 03 F1 0C C4 01 09 85 AD A9 68 AA A4 F4 F9 F8 42 FF 02 00 42 FF 01 09 A3 CB C7 46 97 8F 9D C1 BD 06 D9 03 D6 03 C4 03 DA 72 FF 03 E2 03 C4 03 D6 ...
Por supuesto, las imágenes de estos microordenadores tenían una resolución fija y conocida, por lo que no era necesario almacenarla.
En el caso de imágenes BMP de Windows la cosa cambia, ya que existen muchas variantes de tamaño, formatos de pixel, etc.
Por ejemplo, la imagen que hemos estado usando tiene un tamaño de 98x50 pixels, y ocupa 14800 bytes, es decir, utiliza 3 bytes por pixel.
Aunque la idea es sencilla, implementarla tiene ciertas complicaciones:
- Hay que tener en cuenta que el valor máximo de una secuencia, ya sea de valores repetidos como de valores diferentes, es 256. Por lo tanto, cualquier secuencia más larga debe ser dividida en varios grupos.
- Las secuencias de valores repetidos son relativamente fáciles de localizar, solo es necesario almacenar un contador y el valor repetido, pero para las secuencias de valores diferentes no conoceremos el valor del contador hasta llegar a una secuencia repetida, y entonces tendremos que, o bien haber guardado la secuencia no repetida, o bien volver a leerla para enviarla a la salida.
- Puede haber varias secuencias repetidas consecutivas, por ejemplo, 12 valores C4, 3 valores E9..., pero las secuencias sin repetición siempre estarán entre dos secuencias repetidas, salvo que sea la primera o la última.
Diagrama de flujo
Creo que la mejor manera de visualizar el algoritmo es mediante un diagrama de flujo:
En el diagrama de flujo no se tiene en cuenta el último grupo, que debe ser añadido fuera del bucle
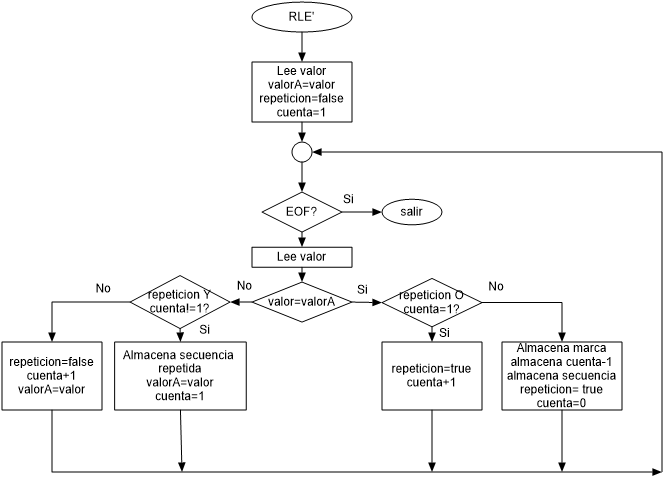
A continuación ahora aplicamos el algoritmo RLE descrito en el diagrama.
Puede ocurrir que una secuencia repetida o no repetida tenga más de 256 elementos. En ese caso dividiremos esa secuencia en grupos de 256 elementos, usando el valor cero como contador, y un último grupo con el resto de elementos.
Por ejemplo, si el valor X aparece 1025 veces, generaremos la siguiente secuencia: 00 X 00 X 00 X 00 X 01 X. Pero con una precaución. Si el valor del resto es el mismo que el de la marca, el primer grupo tendrá 255 elementos, y el último resto+1. Por eso la secuencia generada para esta repetición sería FF X 00 X 00 X 00 X 02 X, con lo que evitamos usar el valor de la marca como contador.
Lo mismo se aplica a secuencias de valores no repetidos, salvo que en este caso no es necesario tener la precaución anterior.
El programa quedaría así:
#include <iostream>
#include <fstream>
#include <iomanip>
//using namespace std;
/* Cabecera BMP:
00: 42 4D BM -> Firma
02: -- -- -- -- -> Tamaño del archivo
06: -- -- -> Reservado
08: -- -- -> Reservado
0A: -- -- -- -- -> Inicio de datos de imagen
0E: -- -- -- -- -> Tamaño de la cabecera
12: -- -- -- -- -> Anchura en pixels
16: -- -- -- -- -> Altura en pixels
1A: -- -- -> Número de planos de bits
1C: -- -- -> Tamaño del punto
1E: -- -- -- -- -> Compresión (0-> No comprimido)
22: -- -- -- -- -> Tamaño de la imagen
26: -- -- -- -- -> Resolución horizontal
2A: -- -- -- -- -> Resolución vertical
2E: -- -- -- -- -> Tamaño de la paleta
32: -- -- -- -- -> Cuenta de colores importantes
*/
void AlmacenaNoRepetida(std::fstream &fe, std::fstream &fs, int cuenta, unsigned char marca) {
unsigned char cuenta256 = '\000';
unsigned char valor;
// Mover el cursor de lectura al principio de la secuencia:
// Ya hemos leído dos valores de una secuencia repetida y
// cuenta incluye el primero de esos valores
fe.seekg(-(cuenta+1), std::ios::cur);
cuenta--; // Descontamos el primer valor de la siguiente secuencia repetida
// Guardamos los grupos de 256 datos, si existen:
while(cuenta > 256) {
fs.write(reinterpret_cast<char*>(&marca), 1);
fs.write(reinterpret_cast<char*>(&cuenta256), 1);
for(unsigned char i=0; i<256; i++) {
fe.read(reinterpret_cast<char*>(&valor), 1);
fs.write(reinterpret_cast<char*>(&valor), 1);
}
cuenta -= 256;
}
// Guardamos el resto:
fs.write(reinterpret_cast<char*>(&marca), 1);
fs.write(reinterpret_cast<char*>(&cuenta), 1);
for(unsigned char i=0; i<cuenta; i++) {
fe.read(reinterpret_cast<char*>(&valor), 1);
fs.write(reinterpret_cast<char*>(&valor), 1);
}
}
void AlmacenaUltimaNoRepetida(std::fstream &fe, std::fstream &fs, int cuenta, unsigned char marca) {
unsigned char cuenta256 = '\000';
unsigned char valor;
// Mover el cursor de lectura al principio de la secuencia:
// Ya hemos leído dos valores de una secuencia repetida y
// cuenta incluye el primero de esos valores
fe.seekg(-(cuenta-1), std::ios::cur);
cuenta--; // Descontamos el primer valor de la siguiente secuencia repetida
// Guardamos los grupos de 256 datos, si existen:
while(cuenta > 256) {
fs.write(reinterpret_cast<char*>(&marca), 1);
fs.write(reinterpret_cast<char*>(&cuenta256), 1);
for(unsigned char i=0; i<256; i++) {
fe.read(reinterpret_cast<char*>(&valor), 1);
fs.write(reinterpret_cast<char*>(&valor), 1);
}
cuenta -= 256;
}
// Guardamos el resto:
fs.write(reinterpret_cast<char*>(&marca), 1);
fs.write(reinterpret_cast<char*>(&cuenta), 1);
for(unsigned char i=0; i<cuenta; i++) {
fe.read(reinterpret_cast<char*>(&valor), 1);
fs.write(reinterpret_cast<char*>(&valor), 1);
}
}
void AlmacenaRepetida(std::fstream &fs, int cuenta, unsigned char valor, unsigned char marca) {
unsigned char cuenta256 = '\000';
unsigned char cuenta255 = '\377';
int resto = cuenta%256;
// Si el resto tiene el mismo valor que marca, quitamos un elemento al
// primer grupo y se lo sumamos al último.
if(cuenta>256 && resto==marca) {
fs.write(reinterpret_cast<char*>(&cuenta255), 1);
fs.write(reinterpret_cast<char*>(&valor), 1);
cuenta -= 255;
}
// Ahora almacenamos el resto de grupos de 256 elementos, si los hay
while(cuenta>256) {
fs.write(reinterpret_cast<char*>(&cuenta256), 1);
fs.write(reinterpret_cast<char*>(&valor), 1);
cuenta -= 256;
}
// Guardamos el resto:
fs.write(reinterpret_cast<char*>(&cuenta), 1);
fs.write(reinterpret_cast<char*>(&valor), 1);
}
int main(int argc, char* argv[])
{
int inicio;
unsigned char marca=1;
bool marcaencontrada=false;
if(argc < 3) {
std::cout << "Usar: RLE <entrada.BMP> <salida.RLE>" << std::endl;
return 0;
}
std::fstream fe(argv[1]);
if(!fe.is_open()) {
std::cout << "Fichero no encontrado" << std::endl;
return 0;
}
std::fstream fs(argv[2], std::ios::out | std::ios::binary);
// El comienzo de los datos se almacena en la posición 0x0A
fe.seekg(0x0a);
fe.read(reinterpret_cast<char*>(&inicio), 4);
// El tamaño de los datos se almacena en la posición 0x22
std::cout << "Inicio de datos: " << inicio << std::endl;
// Generar fichero de salida:
fe.seekg(inicio);
unsigned char valor;
unsigned char valorAnt;
int cuenta=1;
bool repetido= false;
fe.read(reinterpret_cast<char*>(&valor), 1);
valorAnt=valor;
while(!fe.eof()) {
fe.read(reinterpret_cast<char*>(&valor), 1);
if(!fe.eof()) {
if(valor==valorAnt) {
if(repetido || cuenta==1) {
repetido = true;
cuenta++;
} else {
// Almacena secuencia no repetida
AlmacenaNoRepetida(fe, fs, cuenta, marca);
repetido=true;
cuenta=0;
}
} else {
if(repetido && cuenta != 1) {
// Almacena secuencia repetida
AlmacenaRepetida(fs, cuenta, valorAnt, marca);
repetido = false;
valorAnt = valor;
cuenta=1;
} else {
repetido=false;
cuenta++;
valorAnt = valor;
}
}
}
}
// Ultima secuencia:
if(repetido)
AlmacenaRepetida(fs, cuenta, valorAnt, marca);
else {
fe.clear();
AlmacenaUltimaNoRepetida(fe, fs, cuenta+1, marca);
}
return 0;
}
Hay que tener en cuenta que el fichero de salida no contiene una imagen BMP válida, no se ha incluido la cabecera y el método de compresión no es estándar.
Aunque este algoritmo de compresión no es válido para formatos de fichero gráficos, se puede usar para comprimir datos que contengan muchas secuencias de valores repetidos. Por ejemplo, una estación de toma de muestras de temperaturas puede proporcionar muchos valores iguales consecutivos, ya que la temperatura no suele varias de forma brusca ni rápida, estos datos, si se han tomado con la suficiente frecuencia, serían un buen candidato para este tipo de compresión.
Referencias
Estructura de ficheros BMP: Wikipedia.
Algoritmo RLE: Wikipedia.