1 Árbol: Leer un documento XML
Empecemos por leer el contenido de un documento XML desde un fichero en una estructura en árbol.
Elementos
Un documento XML tiene una estructura en árbol, aunque la implementación es algo más compleja que el ejemplo mostrado en el capítulo anterior.
El árbol está formado por nodos, y no todos ellos son iguales, existen varios tipos diferentes.
Por una parte tenemos elementos. Un elemento está compuesto por el contenido entre dos etiquetas, o una etiqueta terminada por '/>', e incluye las propias etiquetas. Por ejemplo:
<elemento1>...</elemento1> <elemento2 />
Cada elemento puede contener a su vez otros elementos, pero también puede contener texto, o incluso estar vacíos.
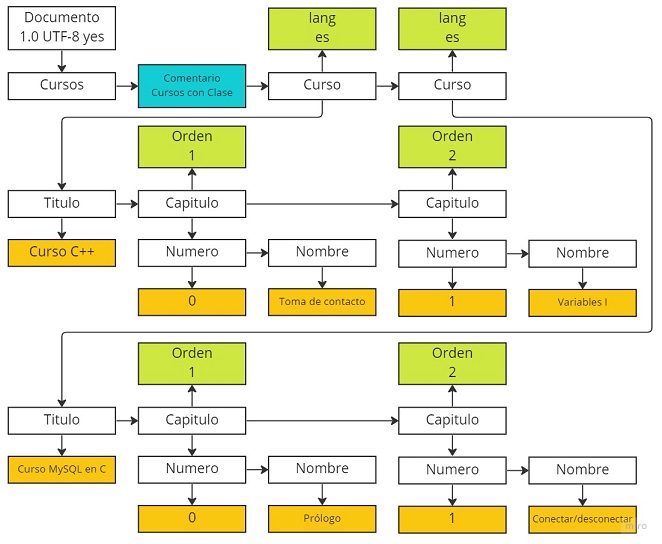
Podemos considerar que el propio documento es un elemento de tipo documento.
En la imagen vemos diferentes tipos de elementos. En blanco nodos de tipo elemento, en azul nodos de tipo comentario, en verde nodos de tipo atributo y en naranja nodos de tipo texto.
La librería libxml2 implementa todos los elementos en estructuras de tipo xmlNode, y cada una de estas estructuras tiene asociadas varias listas enlazadas de nodos.
La lista de nodos es una lista doblemente enlazada, es decir, puede recorrerse en los dos sentidos. Para ello, cada nodo contiene un enlace al nodo siguiente y al anterior (next y prev).
Además, para mantener la estructura en árbol, cada nodo también contiene un enlace a una lista de nodos hijos (children).
En el gráfico, las flechas a la derecha de cada nodo corresponden al enlace next, y las de debajo al enlace children. No se han representado los enlaces prev.
Cada nodo también contiene algunos enlaces a nodos para facilitar la navegación a través de la estructura. El enlace last apunta al último nodo de la lista apuntada por children. El enlace parent apunta al nodo padre. El enlace doc apunta al nodo documento, que es una estructura de tipo xmlDoc, que comparte con la estructura de nodo los primeros nueve miembros.
Otros campos comunes a documentos y nodos son:
- _private que contiene un enlace a datos privados de la aplicación, que podemos usar para nuestros propios fines.
El campo type indica el tipo de nodo o documento, y puede tener uno de los valores del tipo enumerado xmlElementType.
Existen 20 tipos de nodos, que iremos viendo en sucesivos capítulos.
- El campo name contiene el nombre del elemento, cuando se trate de nodos de tipo elemento, que es el texto de su etiqueta. Para los nodos de texto el nombre es 'text', para los de comentario 'comment', etc.
Por otra parte, cada nodo también contiene un enlace a una lista de nodos de atributos, properties. En el gráfico se representan con la flecha encima del nodo.
Los nodos de tipo texto almacenan el texto en el enlace content.
Leer un documento XML
En este primer ejemplo procesaremos un documento XML de ejemplo, para extraer sus elementos, atributos y valores.
// Con Clase Enero 2024
// Ejemplo de lectura de fochero XML
// Añadir en las opciones de compilador:
// xml2.dll para usar la versión dinámica de libxml2
#include <iostream>
#include <string>
#include <libxml/tree.h>
#include <windows.h>
void MostrarHijos(xmlNodePtr, int);
void MostrarAtributos(xmlAttrPtr);
int main()
{
xmlDocPtr doc;
xmlNodePtr node;
LIBXML_TEST_VERSION
SetConsoleOutputCP(CP_UTF8);
doc = xmlReadFile("ejemplo.xml", NULL, XML_PARSE_NOBLANKS);
std::cout << "Nombre: " << doc->URL << std::endl;
std::cout << "Version: " << doc->version << std::endl;
std::cout << "Codificacion: " << doc->encoding << std::endl;
std::cout << "Numero de hijos: " << xmlChildElementCount((xmlNodePtr)doc->children) << std::endl;
node = doc->children;
MostrarHijos(node, 0);
node = doc->children;
node = node->children;
node = node->next;
node = node->children;
node = node->next;
node = node->children;
node = node->next;
std::cout << "\nPath: " << xmlGetNodePath(node) << std::endl;
xmlFreeDoc(doc);
xmlCleanupParser();
return 0;
}
void MostrarHijos(xmlNodePtr node, int nivel) {
while(node) {
if(node->type == XML_ELEMENT_NODE) {
std::cout << std::endl;
for(int i=0; i<nivel; i++) std::cout << ' ';
std::cout << "Elemento: " << node->name << " - ";
MostrarAtributos(node->properties);
} else
if(node->type == XML_TEXT_NODE || node->type == XML_COMMENT_NODE) { // Comentarios o texto
if(!xmlIsBlankNode(node)) {
std::cout << " Nodo tipo(" << node->type << ") " << node->name << " - " << node->content;
}
}
MostrarHijos(node->children, nivel+1);
node = node->next;
}
}
void MostrarAtributos(xmlAttrPtr prop) {
while(prop) {
if(prop->type == XML_ATTRIBUTE_NODE) {
std::cout << " " << prop->name;
std::cout << "(" << prop->children->content << ") ";
}
prop = prop->next;
}
}
Para acceder al árbol necesitamos incluir el fichero "tree.h". En teoría habría que incluir también "parser.h", pero parece que se incluye automáticamente a partir de "tree.h".
Usaremos dos funciones:
- MostrarHijos es una función recursiva que muestra todos los hijos de un nodo, y sucesivamente los de cada nodo que contenga nodos hijos.
- MostrarAtributos muestra los atributos de un elemento, si los tiene.
La macro LIBXML_TEST_VERSION se incluye como precaución, y verifica que la librería de enlace dinámico (DLL) que estamos usando es compatible con la que se usó para compilar el programa.
La función xmlReadFile lee un fichero xml, lo analiza y genera un árbol con su contenido, que se almacena en memoria y devuelve un puntero a una estructura xmlDoc.
El primer argumento es el nombre del fichero o su URL. El segundo permite especificar la codificación de caracteres, puede ser NULL. El tercero sirve para indicar banderas de opciones de análisis xmlParserOption. En nuestro caso hemos usado el valor XML_PARSE_NOBLANKS, que elimina los nodos vacíos. En nuestro ejemplo, si no se añade esta opción, se incluirán los nodos correspondientes a los retornos de línea. Esos nodos se consideran vacíos aunque contengan caracteres de retorno de línea.
Usando esta opción ya no sería necesario verificar si un nodo es vacío mediante xmlIsBlankNode(node).
A continuación mostramos algunos valores del documento xmlDoc, como la versión de xml, la codificación y el número de nodos hijos.
Para calcular el número de elementos de un nodo o documento se puede usar la función xmlChildElementCount. En el caso de un documento XML bien formado ese número debe ser uno, ya que los documentos XML solo pueden contener un elemento.
Dado que los tipos xmlDoc y xmlNode tienen sus primeros nueve campos iguales en tipo y nombre, se puede usar la función xmlChildElementCount tanto con punteros a nodos como a documentos, haciendo al correspondiente conversión de tipo.
Seguidamente iniciamos la variable nodo con el puntero al primer nodo hijo del documento y llamamos a nuestra función MostrarHijos. El primer argumento es el nodo de partida, y el segundo se usa para la indentación, incrementando su valor en cada llamada recursiva.
Esta función recorre la lista de nodos, mostrando para cada uno de los de tipo elemento sus atributos y su lista de nodos hijos, o el texto correspondiente si se trata de nodos de texto o comentarios.
Para mostrar los atributos llamamos a nuestra función MostrarAtributos, pasando como parámetro el puntero al primer nodo properties.
Esta función se limita a recorrer la lista de nodos de tipo atributo, mostrando el nombre y el contenido de su primer nodo hijo, que siempre será de tipo texto.
Finalmente hacemos limpieza, invocando las siguientes funciones:
- xmlFreeDoc(doc), para liberar la memoria asignada al documento.
- xmlCleanupParser() que intenta recuperar toda la memoria global asignada para el procesamiento de la biblioteca.
Tal vez has notado que hay una línea comentada que leería el documento XML llamado "xml_tree.cbp". Este fichero contiene el proyecto del programa de ejemplo, y sí, Code::Blocks guarda los proyectos en un fichero XML.
Ejemplo 1
| Nombre | Fichero | Fecha | Tamaño | Contador | Descarga |
|---|---|---|---|---|---|
| Ejemplo 1 | xml001.zip | 2024-01-23 | 1805 bytes | 381 |